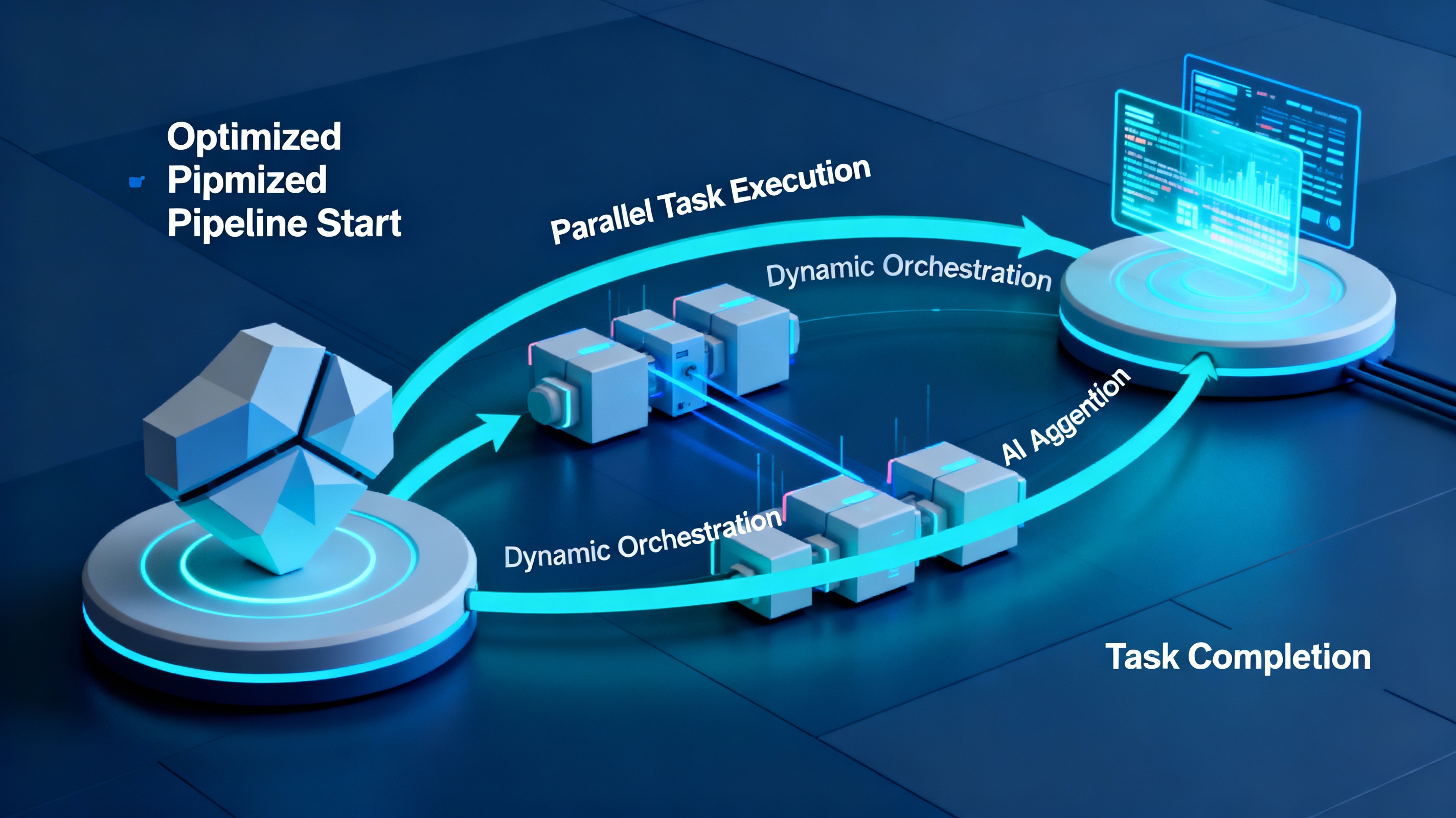
Optimized flow of AI agents refers to the systematic design and enhancement of an agent’s processing pipeline to maximize accuracy, responsiveness, and efficiency in real-world tasks. Achieving this optimized flow requires addressing coordination across multiple system components, managing context and memory, leveraging parallelism, and adapting workflows to the application domain.
Core Workflow Stages of AI Agents
Most AI agents operate across a common sequence of steps, regardless of application[4]:
- Input Reception: Receiving a user’s query or system signal.
- Analysis & Planning: Interpreting the input and generating an action plan.
- Tool/Action Execution: Calling functions, APIs, or invoking reasoning steps.
- Response Delivery: Formatting and transmitting the output.
Each stage introduces latency and potential failure points. Systematic optimization requires analyzing and improving each stage while maintaining overall robustness[1][9].
Key Principles for Optimized Agent Flow
1. Orchestration and Coordination
- The orchestration layer—the logic managing interactions between components—often becomes a hidden bottleneck, introducing unnecessary blocking and inefficient workflows[1][13].
- Specialized orchestration frameworks can reduce this friction by facilitating parallel task execution, skipping redundant steps, and ensuring components communicate efficiently[1].
2. Parallel Processing and Task Decomposition
- Modern agents can run subtasks in parallel, minimizing total processing time compared to traditional sequential logic[2].
- For example, when handling a multi-intent query, different intents (like “book a flight” and “check weather”) can be processed simultaneously rather than in sequence[2][13].
3. Workflow Patterns
| Workflow Type | Description | Use Case Example |
|---|---|---|
| Prompt Chaining | Divides tasks into strict sequences, with output from one step feeding next | Multi-step reasoning, document drafting[7] |
| Routing | Classifies input and distributes to specialized handlers | Customer support triage, model selection[7] |
| Evaluator-Optimizer | Generates a response and then improves it iteratively via feedback | Quality-tuned outputs, safety assurance[7] |
Workflow selection should match the complexity and requirements of the application[7].
4. Memory, Context, and State Optimization
- Preloading hot context: At session start, key information is loaded into fast-access storage, reducing lookup latency for initial responses[1].
- Hybrid memory strategies: Use both short-term (sliding windows) and long-term (retrieval from embeddings or knowledge graphs) memory to balance responsiveness and completeness[5].
- Token compression and smart filtering: Summarize or prioritize information to fit resource constraints without losing essential context[5].
5. Real-Time Data Management and Adaptive Processing
- AI agents adjust their internal flows dynamically, enabling real-time optimization based on operational context—reshuffling task orders, flagging anomalies, or reprioritizing activities in response to changing inputs[2][14].
- Decoupling hot/cold context: Agents use immediate, most relevant data for quick replies, while gradually incorporating slowly loaded or less urgent data in the background[1].
Optimization Techniques
- Critical path analysis: Identify and tightly monitor the minimal set of core functions needed for the agent to fulfill its basic purpose (“critical path”)[1].
- Cache results: Avoid unnecessary recomputation or repeated API calls by caching outputs keyed to input parameters—saves latency and computing resources[1].
- Task specialization: Use routing frameworks to send different user intents to appropriately sized or specialized models, saving on computation for simpler tasks and retaining accuracy for complex ones[7].
Example in Practice: Conversational Agent Flow
- Session Initialization: Preload active user’s profile and prior conversation highlights.
- Input Handling: Immediately parse new user message using preloaded context.
- Parallel Execution: Simultaneously:
- Determine user’s primary intent.
- Retrieve relevant knowledge or documents.
- (If required) Check external APIs for live data.
- Response Construction: Use fast “hot context” for an initial draft; in background, retrieve and integrate deeper “cold context” to refine or supplement reply if time allows.
- Delivery: Send preliminary response rapidly for user experience, while updating or appending details if needed.
Special Considerations
- Multi-agent collaboration: In complex environments (e.g., material flow optimization in supply chain), orchestrator agents manage communication and task assignment among specialized agents for maximum throughput and adaptiveness[14].
- Domain-specific priorities: For real-time decision systems (e.g., industrial automation), ultra-low latency is paramount, so each pipeline component is ruthlessly streamlined and monitored[1][2].
- Resilience and fallback: Robust agents implement fallback strategies, skipping enhancement layers under high load while maintaining core functionalities[1].
Effectively, an optimized AI agent flow is not a tightly fixed pipeline, but an adaptive, orchestrated system that balances latency, throughput, resource use, and output quality—always tailored to the unique requirements of its domain and users[1][2][7].
No comments:
Post a Comment